Dragon Jump is a 2D one-button precision platformer, inspired by games like Super Meat Boy and Geometry Dash. But this isn’t just a game-it’s an educational playground where you can learn how to build an AI from scratch.
In this blog post, I'll show you how to connect a basic AI "brain" that takes random actions to the game, and begin to explore how the AI looks at the game world. Later on, we'll move from simple techniques like if-else logic and [[Decision Tree|decision trees]] to more advanced approaches like genetic algorithms, neural networks, and reinforcement learning.
Before You Start
This page focuses on Dragon Jump specific setup and explains what data the game sends to your AI.
For full environment setup (Python/Poetry or Docker), please use the official PLaiGROUND setup guide.
Scope of this guide
This guide covers Dragon Jump integration only. It does not repeat dependency installation, virtual environment setup, Docker setup, or general troubleshooting from PLaiGROUND docs.
Enabling the AI Mode in the Game
Disclaimer
Local setup currently supports Windows and Linux. If you’re on MacOS, please use the Docker setup from the PLaiGROUND documentation.
Itch.io version
Head over to the Itch.io page and get yourself an executable that runs on your OS. Make sure to remember where you saved your executable, cuz you’ll need it later.
Steam version
If you want to get Dragon Jump on Steam, you’ll need to join the open playtest. Just head to the Steam page, click Request Access, and you’ll be granted immediate entry to the game.
Once installed, feel free to explore - hover over the levels, try a few runs, and get a feel for the gameplay. When you’re ready to start experimenting with AI, it’s time to turn the game into a training environment for your AI brain.
To do this, you’ll need to locate the path to your executable. Use this path to overwrite the default location for the environment executable inside the .config file.
Disclaimer
If you find anything in this setup confusing, drop on by our Discord Channel and give us your feedback on how we can make things better.
Setting Up the AI Brain
I’ve put together a short guide on GitHub that walks you through setting up the Python project where your AI logic will live. You can either set it up to run directly on your PC or use a Docker container for a more consistent environment (I recommend Docker, especially if you want to avoid hardware-related issues).
The guide might look a bit daunting, but once you’ve gone through it, you should find it pretty straightforward. This blog post won’t duplicate setup details from that guide, so we can keep both docs easier to maintain.
How the Game Communicates with Your AI
The game and your AI brain talk to each other using TCP sockets. Here’s how it works:
- every frame, the game (which acts as the client) sends the current state of the Dragon (we’ll call him the agent) to the AI brain (which acts as the server)
- the AI brain then decides what the agent should do (jump or don’t jump) and sends that action back to the game
- this back-and-forth keeps going until the agent reaches the exit gate
Think of it like a walkie-talkie: the game says, “Here’s what’s happening!” and the AI brain replies, “Here’s what to do!”
What the AI “Sees” Each Frame
When building your AI, you’ll be making decisions based on what the game sends it every frame. That data is split into three main parts: State, Info, and Reward.
The State
This is the core data your AI will use to decide what to do next.
The game sends over a chunk of data called "obs" (short for observation), which includes:
- Grid data - 49 pixels - each one denoting the type of object your character sees
- Extra features - 8 values - containing:
- Facing direction (normalized X and Y)
- Character velocity (also normalized X and Y)
- Whether you’re on the floor (boolean value)
- Whether you’re on a wall (boolean value)
- Jump peak percentage (single normalized value)
- tells you how close you are to your jump apex
- Has powerup (boolean value)
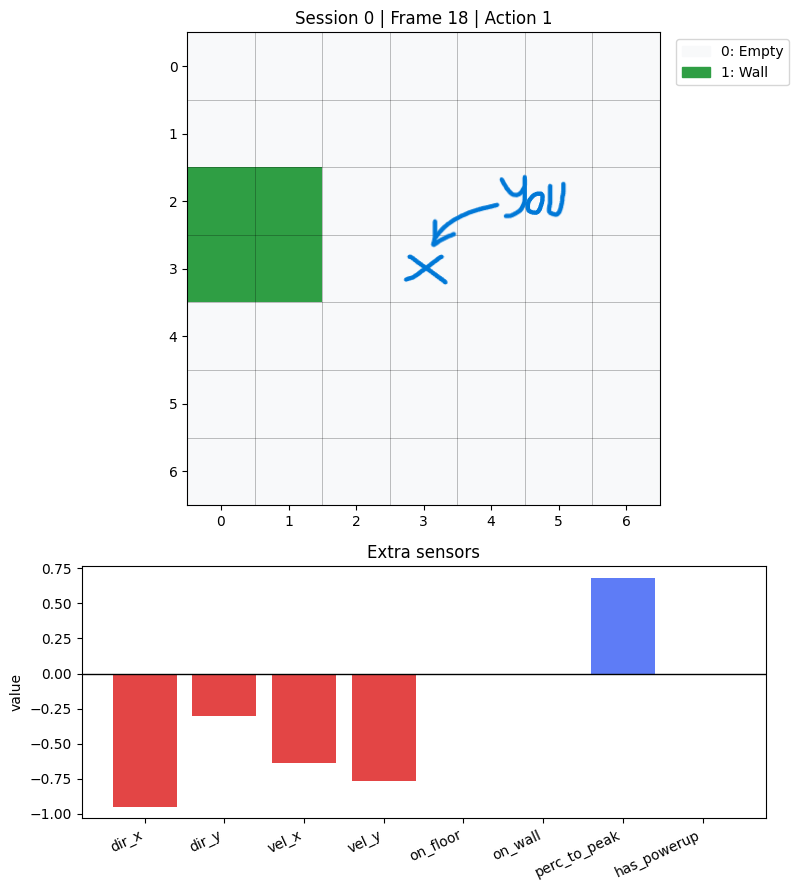
In practice, you can think of "obs" as one feature vector per frame:
- 49 grid values + 8 extra features = 57 total input features
- this 57-value vector is exactly what you usually feed as X when training a model (Decision Tree, NN, etc.)
- your label (y) depends on what you’re learning (for example: jump / don’t jump)
Two practical notes:
- most values are already normalized or boolean, which makes them easy to use directly as model inputs
- keep your model inputs limited to
"obs"for fair training;infois mostly for debugging and may not always be available
The Info
This is extra data mainly for debugging and testing your AI. Don’t rely on this for actual training or competition-it might not always be available.
Here’s what you’ll find:
global_position– the Dragon’s location in the game worldfacing_direction– whether the Dragon is looking left or rightstate– tells you what the Dragon is doing: Idle, Running, Jumping, Falling, Walled, etc.tile_names– a lookup table for the Grid data values
The Reward
This is only used when training AIs that learn over time (like ones using genetic algorithms or reinforcement learning). The reward helps the AI figure out whether it made a good move or not.
Here’s how it works:
- -0.01 points for every frame spent in the level (to encourage faster completion)
- +0.01 points for every frame it gets closer to the exit
- +0.1 points for getting a personal best on getting closer to the exit
- +100 points for reaching the exit gate
Fun fact
We’re calculating the progress of the character towards the goal by using Flow Fields. That way we take into account walls and we’re able to support all states the character may be in.
Keep in mind: rewards are only available during training-they won’t be there when your AI is competing against others.
About Actions
In Dragon Jump you control the Dragon by pressing the SPACE BAR. That means that the action space is a Discrete Action Space where the action is either Jump (1) or Don’t Jump (0).
You can decide whether to jump or not based on a lot of factors, such as:
- if there’s an object that the dragon can jump over based on the grid data
- whether the dragon is currently on a wall or on the floor
- it it’s close to the exit and it’s facing the right direction
Deeper Dive into the Python Code
The wrapper
First a wrapper over the game is created. This is done to ensure everything is streamlined.
env = StableBaselinesGodotEnv()Reset the environment
To make sure the environment and the code is synchronized, you’ll need to reset it before doing anything else.
obs = env.reset()The reset will also return the first set of observations that you’ll use to take your first action.
Take action
Once you decided on what action you want to take, your agent needs to take a step in the environment.
obs, reward, done, info = env.step(actions)The step will return some valuable information regarding what happened after your agent acted, that will be useful when deciding on what’s the next action it may take.
What do those values mean?
- obs: dict - the observation of the current state of the game (contains obs and obs_2d)
- reward: float - the thing your agent will optimise towards maximising
- done: bool - whether the game is playing or it ended
- info: dict - additional information regarding the game
Repeat
The done flag will be set to true once the agent either completes the map or a certain number of in-game steps have passed.
Disclaimer: I don’t remember what’s the number of steps I chose for this environment, so you can figure out the reason it ended by what was the last reward it received. If the reward is higher than usual and you have a seemingly random number of steps: Congrats! You did it! 🍻