What are GLMs
Generative Language Models (GLMs) are a type of Generative Models that take in tokens as inputs and generate tokens as outputs. A token can be either a word, a syllable or a letter, depending on how the model was setup.
Simpler put, they are glorified autocomplete systems powered by AI. They generate text (be it words, sentences or essays) based on the input they get, whether that’s a question, JSON or image.
By the way, it’s a pain to type Generative Language Models over and over, so I’ll call them GLMs from now on.
Why they exist
GLMs were initially built to see whether a Machine Learning Model can build good statistical relationships between words - basically how good they could get at autocomplete.
Over time, researchers figured that if GLMs get good at predicting the next word in a sequence, they start learning a lot about language, worldly facts and even start mimicking human reasoning. Now, GLMs are pushed to the limits to store information, find patterns in language and to make said information easier to access.
Today people use GLMs (like ChatGPT) for a bunch of stuff. But I like to think of them as three buckets:
- getting information: by asking the AI different questions
- processing text: extracting information from messy text or summarizing text
- automating stuff: by giving your AI a task (like me needing a coupon code) so it will:
- uses a function to search the internet
- grabs the content of a webpage
- extracts the relevant info
- and gives you the final answer
There are a ton of things you can do with GLMs. But keep in mind: they’re powerful, not magical. And the better you understand how they work, the easier it is to use them - and to work around their limitations.
How they work
There were a bunch of iterations done on GLMs to get to something like ChatGPT.
ヽ(`Д´)⊃━☆. * ・ STORY TIME
At first, researchers started small. They trained the model on simple sentences, and thought it to guess what word would come next.
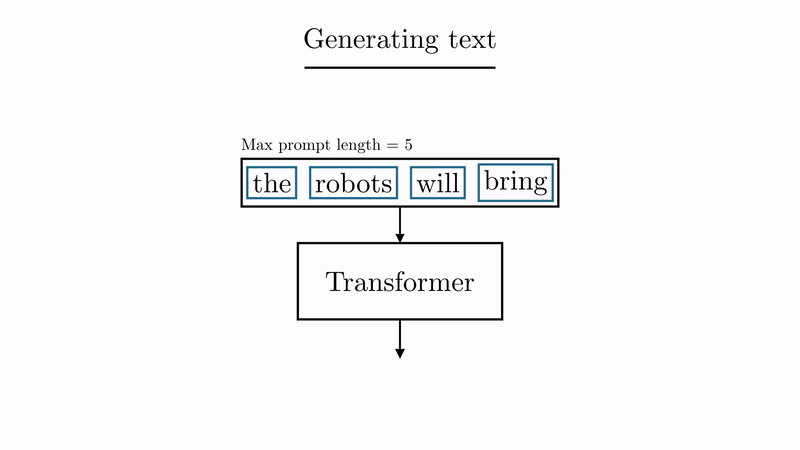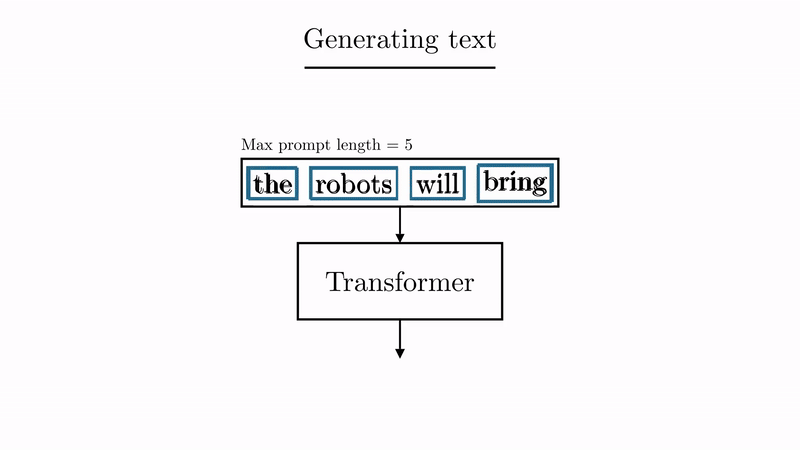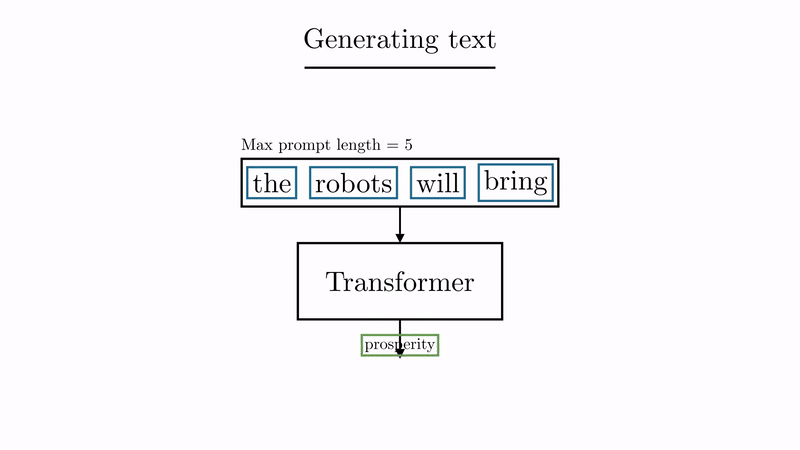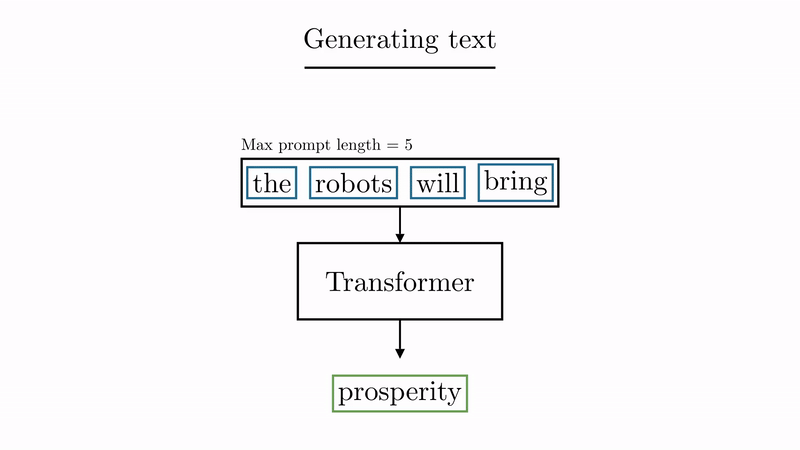
source: animated-transformer
Once researchers saw that the AI was getting pretty good on these simple examples, they tried new sentences. And more. And more difficult. Eventually … they ended up feeding it the internet (or at least part of it). Conversations, blogposts, video transcriptions, you name it.
Getting tired of just feeding it data, the researchers thought:
Researcher 1: What if we train the AI to speak like a human?
Researcher 2: That way, we’ll have others test how well it remembers the information.
And that kids is how I met ChatGPT.
Limitations
Cool stuff. So, if GLMs are so powerful, why don’t we just use them for everything? Why do we even need other kinds of language models?
Well… there are a few reasons.
GLMs like shrooms
There’s a thing with GLMs called hallucinations. What it means is that they will sometimes make things up confidently when they’re faced with questions they haven’t seen before.
Think of it like this: show a caveman a smartphone and ask it what it is. It would probably make up some weird but confident explanation. When you ask a GLM something it knows nothing about, it starts autocompleting with the most plausible answer based on what it knows.
Remember, GLMs are just glorified autocomplete systems. They don’t have an internal switch to make them say “I don’t know”, not yet at least. So they’ll just guess when you ask them about things they don’t know.
The downside is that you don’t know when they’re guessing.
But there’s a fix for this, you can give them some context. If you give the GLM a document, a snippet of code or some structured data, it can use that information to answer your question. Similar to it doing extraction + summarization.
GLMs only know the training data
Tying back to the previous section, we don’t know what the GLM has seen during training. And if we were to use a GLM, for example, as a translator we will need to properly test it. Mainly because we don’t know how much it has seen from both languages to be able to map words from one language to another.
I really wanted to give you an example of how GPT miss-translates Romanian idioms, but unfortunately it seems that they included that in the training data 🥲
With great power comes great power bills
GLMs are incredibly versatile and easy to use - but usually they do more than we actually need them for.
Example
Say you want to buy a laptop. You might want:
- good battery life - so it will last longer
- a sharp screen - so you’ll see the image clearer
- powerful hardware - so you can play games or use LLMs locally
- a compact form-factor - so you can actually carry it with you
And the more things you want your laptop to do, the more expensive it’s going to get.
So if a laptop is more expensive than a tablet because it has more features some Generative Models are more costly than other LLMs - and also require more hardware to run and train.
Maybe it is going to take longer to find a good deal on a tablet, but it should be worth it in the long run.
So not only do GLMs require more hardware to run efficiently, but training them is also computationally expensive (think thousands of GPUs running for weeks).
They’re wonderful for prototyping, experimenting and validating that the thing you want is doable. But if you have the time and want to learn about other model types, you’ll end up having a less bulky, faster and cheaper model.