Overfitting and Underfitting
Think of it like this: your AI can either be a nerd or a slacker.
- the nerd learns his lessons by heart - but can’t survive once he leaves school and meets the real world
- the slacker says he’s “done” way too soon - but can’t figure anything out cuz he never paid attention in class
A nerd is an AI that overfitted while the slacker represents an AI that underfitted.
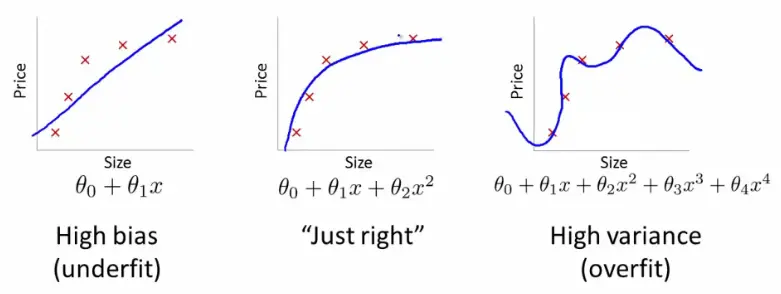
Overfitting
The model memorized the training set - quirks, noise, weird one-offs - instead of learning something that generalizes.
Classic smell: training looks amazing BUT test / validation looks sad. It “knows” the examples you showed it and gets lost on anything new.
“I can recite last year’s exam. Ask me a new question and I’m toast.”
What people do about it: more data (when you can), simpler models, regularization, early stopping, or knobs that stop the model from growing too greedy - like the depth / leaf limits on a Decision Tree.
Underfitting
The model is too simple (or too constrained) to capture what’s actually going on. It’s like using a straight line when the data clearly bends.
You’ll usually see meh scores everywhere - training and test both look “fine but not great,” because it never really got the pattern in the first place.
What people do about it: more useful features, a richer model, or loosening limits that were strangling it (depending on what you’re training).
Quick sanity check
If you only stare at training metrics, you’re grading the model on the answers it already saw. Peek at held-out data ( test) too - that’s where underfitting vs overfitting actually shows up.